Look, I’ve been writing about AI models for years now, and every few months something drops that makes me sit up straight. The Claude Opus 4.6 release on February 5, 2026, was one of those moments. Anthropic basically took their smartest model, cranked everything up a few notches, and handed it back to us. And honestly? It feels different this time.
So let me walk you through everything — what Anthropic Claude Opus 4.6 actually is, what’s new, how it stacks up against GPT-5.2, and whether it’s worth your money. No fluff. Just what I’ve seen with my own eyes.
What Exactly Is Claude Opus 4.6?
Claude Opus 4.6 is Anthropic’s flagship large language model — their most intelligent model, as they put it. It’s the successor to Claude Opus 4.5, and it focuses heavily on agentic coding, deep reasoning, and something that really caught my attention: self-correction.
What does that mean in plain English? It plans before it acts. It catches its own mistakes. And it doesn’t just do one thing and stop — it sustains longer, more complex tasks without falling apart halfway through. If you’ve ever had an AI model lose the plot midway through a big coding project, you know exactly why this matters.
The model is available right now on claude.ai, the Claude API (model ID: claude-opus-4-6), and every major cloud platform including Microsoft Foundry, Amazon Bedrock, and Google Cloud Vertex AI.
Must Read : AI Regulation New Today: What’s Actually Changing?
The Features That Actually Matter
Let me break down what’s genuinely new here — not marketing talk, but the stuff that changes how you work.
1M Token Context Window
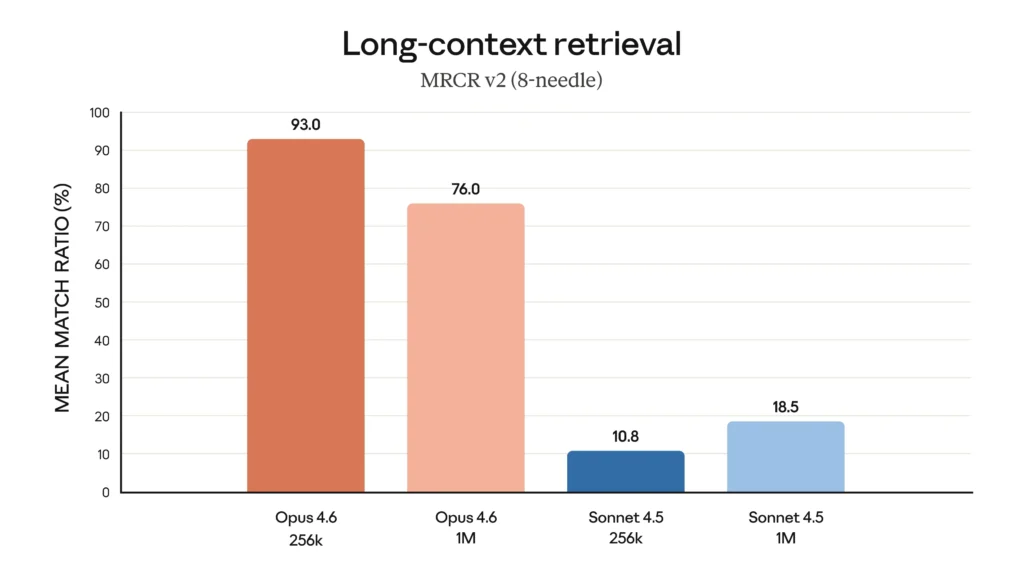
This is huge. For the first time ever in an Opus-class model, you get a 1 million token context window in beta. That’s roughly the equivalent of feeding it multiple entire books at once. If you work with long legal documents, massive codebases, or research papers, this is a game-changer.
On the MRCR v2 benchmark at 1M context, Opus 4.6 scores 76% — compared to Sonnet 4.5’s pathetic 18.5%. That’s not an incremental improvement; that’s a different league.
Must Read : My Real 2026 Experience with Grok AI Spicy Mode
Adaptive Thinking
Here’s something clever. Previously, you had to manually toggle extended thinking on or off. Now, Claude decides for itself whether it needs to think deeper based on how complex your prompt is. Simple question? Quick answer. Complex multi-step problem? It slows down and reasons it out.
You can also control this with an effort parameter — low, medium, high, or max — so you’re always in the driver’s seat when it comes to balancing speed and thoroughness.
Context Compaction
We’ve all hit that wall where a long conversation just… breaks. The model forgets what you said earlier, or performance tanks.
Opus 4.6 introduces context compaction, which automatically summarizes earlier parts of a conversation when you’re approaching the token limit. Your agent keeps running. Your workflow doesn’t stop. It just works.
Agent Teams in Claude Code
This one blew my mind. You can now spin up multiple independent Claude agents that work in parallel as a team. One agent leads and coordinates, while teammates handle execution — each with their own context window.
Think of it like having a small dev team, except they’re all AI. It’s ideal for codebase reviews, large refactoring jobs, or any task that splits into independent chunks.
128K Output Tokens
The output limit has doubled from 64K to 128K tokens. This means longer responses, bigger code outputs, and more room for the model to think before it answers. If you’ve ever gotten a response cut short right when it was getting good, this fix is for you.
How Does It Perform? The Benchmarks
I’ll be real, I usually skim past benchmarks. But Opus 4.6’s numbers are hard to ignore.
Benchmark Results
| Benchmark | What It Measures | Opus 4.6 Result |
| Terminal-Bench 2.0 | Agentic coding | #1 overall |
| Humanity’s Last Exam | Complex reasoning | #1 among all frontier models |
| GDPval-AA | Knowledge work (finance, legal) | +144 Elo over GPT-5.2 |
| BrowseComp | Finding hard-to-find info online | #1 overall |
| SWE-bench Verified | Software engineering | Top-tier score |
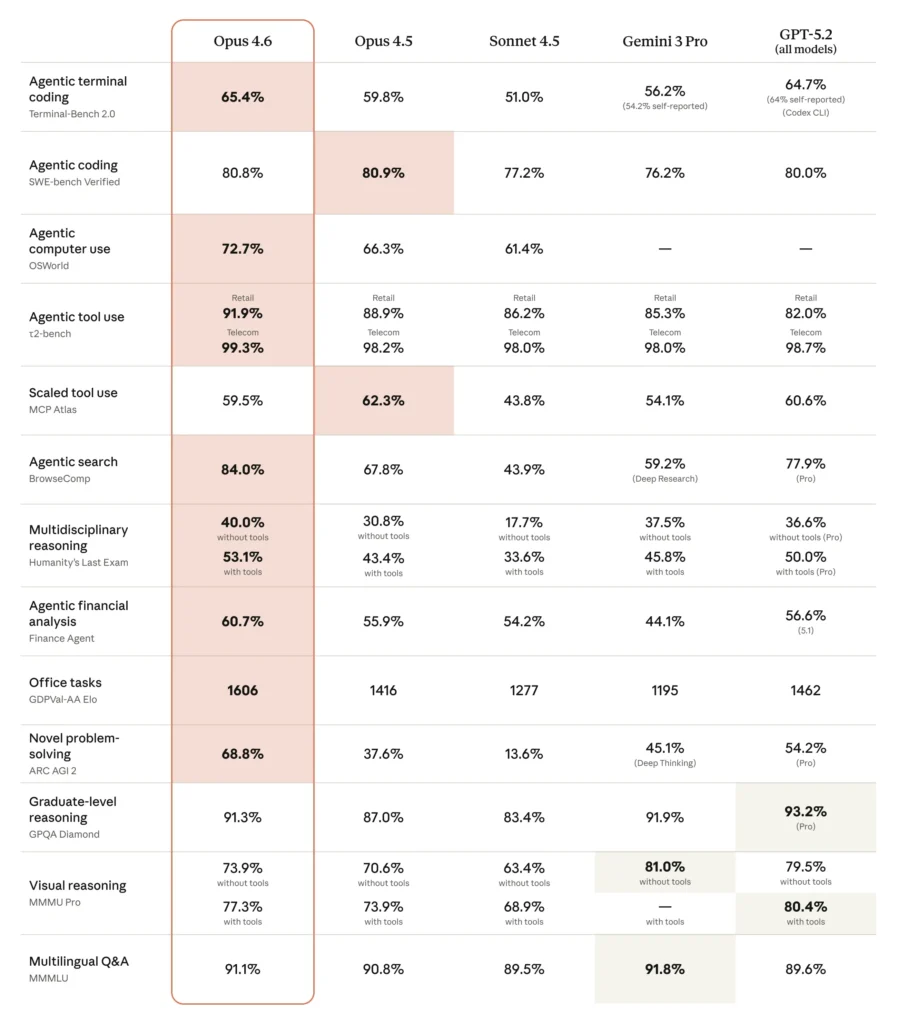
On GDPval-AA — which measures real-world economically valuable tasks — Opus 4.6 beats GPT-5.2 by 144 Elo points and its own predecessor by 190 points. That’s not a rounding error; that’s dominance.
In head-to-head testing by Tom’s Guide across 9 tough challenges, Claude Opus 4.6 consistently delivered more complete, more instructive answers.
Must Read : Leonardo AI Review 2026
Claude Opus 4.6 Pricing
Here’s the good news: Anthropic didn’t raise the price. You get all these upgrades at the same cost as Opus 4.5.
Pricing Table
| Tier | Input | Output |
| Standard (up to 200K) | $5/MTok | $25/MTok |
| Long Context (200K+) | $10/MTok | $37.50/MTok |
| Batch Processing | $2.50/MTok | $12.50/MTok |
| US-Only Inference | 1.1× standard | 1.1× standard |
You can also save up to 90% with prompt caching and 50% with batch processing. For the 1M context window beta, premium pricing kicks in above 200K tokens.
Who Should Actually Use This?
Developers and engineers if you’re working with large codebases, debugging, or building agentic workflows, this is the best coding model available right now.
Enterprise teams the GDPval-AA results speak for themselves. Financial analysis, legal document review, and research workflows all get a massive boost.
Content creators and researchers the 1M context window and adaptive thinking make this ideal for anyone working with massive amounts of text.
And if you’re already on Claude, migrating from Opus 4.5 to 4.6 is seamless since the pricing is identical.
FAQs
What is Claude Opus 4.6?
Claude Opus 4.6 is Anthropic‘s most intelligent AI model, released on February 5, 2026. It specializes in agentic coding, deep reasoning, long-context tasks, and self-correction.
When was Claude Opus 4.6 released?
The Claude Opus 4.6 release date is February 5, 2026. It’s available on claude.ai, the Claude API, Microsoft Foundry, Amazon Bedrock, and Google Cloud Vertex AI.
How much does Claude Opus 4.6 cost?
Standard pricing is $5 per million input tokens and $25 per million output tokens — the same as Opus 4.5. Long-context usage above 200K tokens costs $10/$37.50 per million tokens.
Is Claude Opus 4.6 better than GPT-5.2?
On several key benchmarks, yes. Opus 4.6 leads GPT-5.2 on GDPval-AA by 144 Elo points, tops Terminal-Bench 2.0, and outperforms it on BrowseComp and Humanity’s Last Exam.
What is adaptive thinking in Claude Opus 4.6?
Adaptive thinking lets Claude automatically decide how much reasoning effort to apply based on the complexity of your prompt, instead of requiring you to manually toggle extended thinking on or off.
Does Claude Opus 4.6 support a 1M token context window?
Yes, a 1 million token context window is available in beta — a first for Opus-class models. Premium pricing applies for prompts exceeding 200K tokens.